Random Forests
Random Forests é um algoritmo de aprendizado de máquina que combina várias árvores de decisão independentes para realizar tarefas de classificação ou regressão.
Ele pertence à categoria de métodos ensemble, que buscam melhorar a precisão e robustez das predições combinando diferentes modelos para se obter um único resultado.
Construção de um Random Forests
Etapas
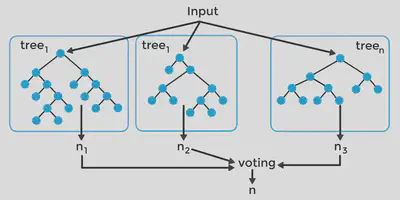
- Amostragem aleatória com reposição (bootstrap) dos dados de treinamento
- Construção de uma árvore de decisão para cada amostra bootstrap
- Votação (classificação) ou média (regressão) dos resultados das árvores
Amostragem Bootstrap
- Seleciona-se aleatoriamente uma amostra dos dados de treinamento com reposição
- Diferentes amostras podem conter itens duplicados ou omitir outros
- Garante diversidade nas árvores construídas
Para cada amostra bootstrap gerada, os dados são divididos utilizando os atributos que maximizem a pureza dos nós
-
Critérios de divisão: Gini Index, Entropia, Ganho de Informação, etc.
-
Construção recursiva até atingir critérios de parada (profundidade máxima, pureza mínima)
Como realizar a classificação?
- A classificação é obtida por votação majoritária dos resultados de cada árvore
- Cada árvore possui um peso igual na votação final
- Resultado: classe mais frequente entre todas as árvores
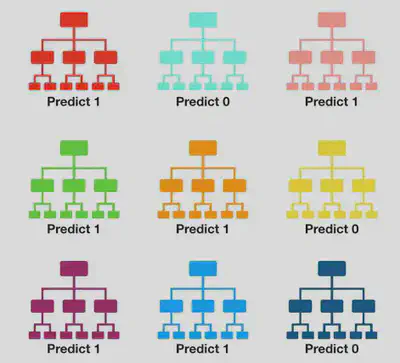
Qual a classe predita?
Pela regra da maioria: classe 1
Vantagens do Random Forests
- Trata efetivamente problemas de overfitting
- Lida bem com dados ausentes e valores discrepantes
- Capaz de lidar com atributos de diferentes tipos (numéricos, categóricos)
- Reduz a variância e melhora a precisão em comparação com uma única árvore
Support Vector Machine (SVM)
O SVM (Support Vector Machine) é um algoritmo de aprendizado de máquina amplamente utilizado em problemas de classificação.
Ele é especialmente útil quando os dados são não linearmente separáveis ou quando se deseja encontrar um hiperplano ótimo para separação das classes.
Princípio básico
O objetivo do SVM é encontrar um hiperplano de separação ótimo que maximize a margem entre as classes.
Hiperplano de Separação
Para problemas de classificação binária, um hiperplano de separação é uma superfície que divide o espaço de características em duas regiões, uma para cada classe. Neste caso, esse hiperplano é uma reta!
Em problemas multiclasse, pode ser um plano ou uma superfície mais complexa.
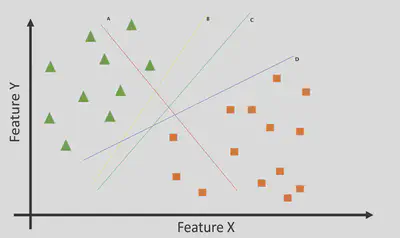
Temos aqui 4 hiperplanos (A, B, C e D). Qual o melhor?
Vetores de Suporte
Os vetores de suporte são os pontos de dados mais próximos ao hiperplano de separação. Eles são fundamentais para o SVM, pois definem a posição do hiperplano e a margem.
Margem
A margem é a distância entre o hiperplano de separação e os vetores de suporte mais próximos. O objetivo do SVM é maximizar a margem, pois isso aumenta a capacidade de generalização do modelo.
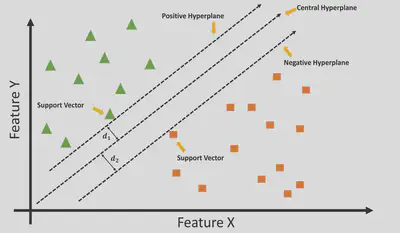
Para encontrar o hiperplano ótimo, caímos em um problema de otimização com restrição, que pode ser resolvido utilizando a técnica dos Multiplicadores de Lagrange!
Mas e se tivermos problemas não linearmente separáveis?
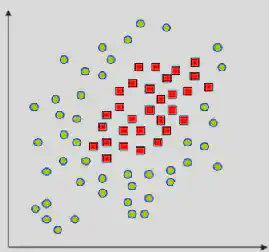
O SVM é um algoritmo que inicialmente trabalha com dados linearmente separáveis. No entanto, muitas vezes encontramos conjuntos de dados que não podem ser separados por um hiperplano linear. É aí que entra o Kernel Trick.
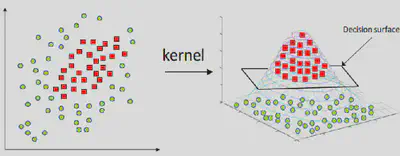
Kernel Trick
O Kernel Trick (Truque do Kernel) nos permite mapear os dados para um espaço de características de dimensão superior, onde se tornam linearmente separáveis.
Isso é feito através de uma função chamada kernel, que calcula o produto interno entre dois vetores nesse espaço de características.
Existem diferentes tipos de kernels que podem ser utilizados, como o linear, polinomial, RBF (radial basis function) e sigmoide. Cada um desses kernels possui suas características e é escolhido com base nas características do conjunto de dados e no tipo de separação não linear esperada
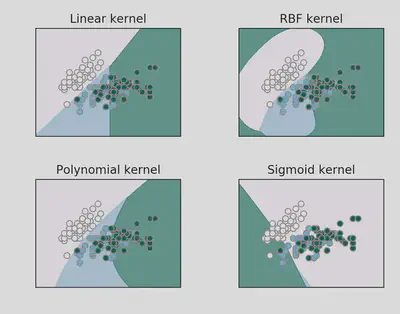
Escolha do kernel
A escolha do kernel adequado é importante para obter um bom desempenho do SVM. É necessário analisar as características dos dados e testar diferentes kernels para encontrar o que melhor se adapta ao problema em questão
O uso do Kernel Trick pode melhorar o desempenho do SVM ao permitir que ele modele relações não lineares nos dados. No entanto, é preciso ter cuidado para evitar o overfitting, garantindo que o modelo generalize bem para dados não vistos.
SVM para problemas multiclasse
O SVM como definido funciona para duas classes. O que fazemos então se tivermos mais de duas classes?
One-vs-One (OVO)
Nessa abordagem, é criado um classificador SVM para cada par de classes possível. Cada classificador é usado para classificar uma instância de entrada e a classe com mais votos é selecionada como a classe final.

Essa abordagem pode ser computacionalmente mais intensiva em problemas com um grande número de classes, pois requer treinar um número maior de classificadores
One-vs-All (OVA)
Essa abordagem consiste em treinar um classificador SVM para cada classe, onde cada classificador é treinado para distinguir uma classe específica das demais classes combinadas.
Durante a fase de teste, cada classificador é usado para classificar uma instância de entrada e a classe com a maior probabilidade é selecionada como a classe final.
