Tratamento de ruídos

-
O ruído pode ser causado por vários fatores, como erros de entrada de dados, erros de medição, valores atípicos, variabilidade aleatória ou viés.
-
Existem algumas abordagens comuns para o tratamento de ruídos em um conjunto de dados, incluindo:
-
Identificação e remoção de valores atípicos: valores que são muito diferentes dos outros valores no conjunto de dados podem ser identificados como valores atípicos.
- Esses valores podem ser removidos do conjunto de dados ou tratados separadamente para minimizar o impacto no resultado da análise.
- Correção de erros de entrada de dados: erros de entrada de dados podem ser corrigidos por meio da revisão manual dos dados ou por meio de algoritmos de detecção e correção automática de erros.
- Normalização ou padronização de dados: a normalização ou a padronização de dados pode ser usada para tornar os dados comparáveis e interpretáveis, especialmente quando os dados têm unidades diferentes ou escalas diferentes.
- Utilização de técnicas de suavização de dados: técnicas de suavização, como média móvel ou suavização exponencial, podem ser usadas para reduzir o impacto do ruído nos dados.
- Utilização de técnicas de agrupamento: técnicas de agrupamento, como análise de cluster, podem ser usadas para identificar padrões em um conjunto de dados e reduzir o impacto do ruído.
Como identificar um valor atípico?
-
Gráfico box-plot
-
Z-score: valores com um z-score maior do que um limite (geralmente 3) são considerados valores atípicos.
-
Intervalo interquartil (IQR): valores abaixo de Q1 - 1,5 x IQR ou acima de Q3 + 1,5 x IQR são considerados valores atípicos.
-
Método de DBSCAN: é um algoritmo de clusterização que agrupa pontos de dados que estão próximos uns dos outros e identifica valores que não estão próximos a nenhum cluster, o que pode ser um sinal de valores atípicos.
- Quaisquer que sejam as técnicas empregadas, a documentação e o registro das etapas de limpeza de dados são essenciais para garantir a reprodutibilidade, transparência, colaboração, auditabilidade e controle de qualidade em análises de dados.
Integração de dados
-
Integração de dados é o processo de combinar dados de múltiplas fontes em um único conjunto de dados coerente e integrado.
-
O objetivo da integração de dados é criar um conjunto de dados mais completo e preciso, permitindo análises mais abrangentes e informadas.
-
Algumas técnicas comuns para integração de dados são:
-
Fusão de dados: é o processo de combinar dois ou mais conjuntos de dados com base em uma chave comum.
- Por exemplo, dados de clientes de uma empresa podem ser fundidos com dados de vendas, com base no número de identificação de cliente.
-
-
Análise de correspondência: é uma técnica de integração de dados que permite combinar informações de diferentes fontes, com base em uma análise de correspondência de variáveis.
- Por exemplo, dados de vendas de uma empresa podem ser combinados com dados demográficos, com base em correspondências de variáveis, como localização geográfica ou faixa etária.
- Independentemente da técnica usada, é importante lembrar que a integração de dados pode ser complexa e demorada e pode envolver a identificação e correção de inconsistências nos dados.
Redução de dados
-
A redução de dados é uma técnica usada para diminuir a dimensão de um conjunto de dados, ou seja, reduzir o número de variáveis ou características que compõem o conjunto de dados.
-
Existem várias razões para reduzir os dados, incluindo:
- Simplificar a análise de dados, tornando-a mais fácil e mais rápida de ser executada;
- Reduzir o tempo de processamento e armazenamento dos dados;
- Melhorar a qualidade dos dados, eliminando variáveis irrelevantes ou redundantes que possam afetar negativamente a análise;
- Preparar os dados para a entrada em um modelo de aprendizado de máquina.
-
Algumas técnicas comuns para redução de dados:
-
Análise de Componentes Principais
-
Seleção de atributos
-
Amostragem
-
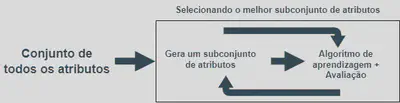
Seleção de atributos
-
A seleção de atributos é um processo de pré-processamento de dados que envolve a escolha dos atributos (variáveis) mais relevantes para a análise.
-
O objetivo da seleção de atributos é reduzir a dimensionalidade dos dados, eliminando características irrelevantes e redundantes, e, assim, melhorar a precisão e a eficiência da análise.
-
Seleção baseada em filtro: Essa técnica usa métricas estatísticas para avaliar a relevância dos atributos e seleciona aqueles que têm maior correlação com a variável de interesse.
-
Métodos de filtragem: coeficiente de correlação, ganho de informação e o teste de qui-quadrado.

- Seleção baseada em wrapper: Essa técnica envolve a seleção de atributos por meio de um modelo de aprendizado de máquina, que é treinado em um conjunto de atributos selecionados. O modelo é avaliado usando validação cruzada e as atributos são selecionados com base no desempenho do modelo.
- Métodos wrapper: Forward stepwise selection, Backward Elimination, Bi-directional stepwise selection & elimination.

-
Seleção baseada em incorporação: Essa técnica envolve a seleção de atributos durante o processo de treinamento do modelo de aprendizado de máquina.
-
O modelo é treinado com todas os atributos e, em seguida, os atributos são removidos com base em sua importância para o modelo.
- Métodos de incorporação: Regressão LASSO, Árvores de decisão…