Limpeza de dados
O que é limpeza de dados?
-
Limpeza de dados é o processo de identificar, remover ou corrigir dados imprecisos, incompletos, inconsistentes, duplicados ou irrelevantes em um conjunto de dados.
-
É uma etapa importante no processo de análise de dados, uma vez que dados sujos podem afetar negativamente a qualidade e confiabilidade dos resultados da análise.
Identificação de problemas
-
Existem várias técnicas para identificar problemas de limpeza de dados em um conjunto de dados. Algumas das técnicas mais comuns incluem:
-
Análise visual: pode-se inspecionar o conjunto de dados para identificar erros óbvios, como valores ausentes, valores que não fazem sentido ou valores extremos.
- Estatística descritiva: realizar uma boa análise descritiva. Valores extremos ou valores que estão muito longe do intervalo interquartil, por exemplo, podem ser indicativos de problemas de limpeza de dados.
- Gráficos de distribuição: analisar os gráficos de distribuição para cada variável e observar padrões incomuns na distribuição dos valores, como bimodalidade, assimetria ou outliers.
-
Análise de correlação: analisar as correlações entre as variáveis e procurar relações que não fazem sentido ou que não deveriam existir.
-
Análise de consistência: comparar valores em diferentes variáveis para ver se eles são consistentes entre si. Por exemplo, se uma pessoa é descrita como tendo 2 metros de altura e 30 kg de peso, pode haver um problema de limpeza de dados.
Tratamento de dados faltantes

“The idea of imputation is both seductive and dangerous” (R.J.A Little & D.B. Rubin)
-
A escolha do método de tratamento de valor ausente depende do tipo de valor ausente identificado.
-
Basicamente, existem dois tipos de valores ausentes: aleatórios e não aleatórios
-
MCAR (missing completely at random): ocorrem de forma completamente aleatória e não estão relacionados com as outras variáveis do conjunto de dados.
- Por exemplo, em uma pesquisa por telefone algumas das respostas não foram registradas devido a problemas técnicos que ocorreram aleatoriamente durante a coleta dos dados.
-
MNAR (missing not at random): são valores ausentes que estão relacionados com outras variáveis do conjunto de dados e podem levar a enviesamento na análise dos dados.
- Por exemplo, em uma pesquisa sobre saúde mental, as pessoas que sofrem de depressão tendem a não responder perguntas sobre sua condição de saúde mental.
Como identificar o mecanismo gerador dos dados faltantes?
-
Para identificar valores ausentes MCAR, uma técnica é analisar a distribuição de valores ausentes em relação às outras variáveis do conjunto de dados.
-
Se não houver correlação entre a ausência de valores e outras variáveis, é provável que os valores ausentes sejam MCAR.
-
Também é possível realizar testes estatísticos para verificar se a distribuição dos valores ausentes é aleatória ou não.
-
Já a identificação de valores ausentes MNAR é mais complexa, pois eles estão relacionados a outras variáveis do conjunto de dados e, portanto, é mais difícil determinar se eles são completamente aleatórios ou não.
-
Algumas técnicas para identificar valores ausentes MNAR incluem:
- Análise de padrões de resposta: é possível analisar como objetos com valores ausentes se diferenciam daqueles que não têm valores ausentes, em termos dos atributos. Se os indivíduos com valores ausentes são significativamente diferentes em relação a essas variáveis, é provável que os valores ausentes sejam MNAR.
- Análise de correlação: é possível analisar a correlação entre as variáveis com valores ausentes e outras variáveis no conjunto de dados. Se houver uma correlação significativa entre as variáveis, é possível que os valores ausentes sejam MNAR.
-
Análise visual: é possível realizar análises gráficas para verificar se há algum padrão de valores ausentes que sugira que eles não são aleatórios.
- Por exemplo, pode-se criar um gráfico de dispersão de uma variável em relação a outra, marcando as observações com valores ausentes. Se houver um padrão na localização dos valores ausentes no gráfico, é possível que eles sejam MNAR.
Tratamento de valores ausentes completamente aleatórios
-
O tratamento de valores ausentes completamente aleatórios (MCAR) é relativamente simples, pois os valores ausentes são independentes das demais variáveis e podem ser tratados sem viés.
-
Algumas técnicas comuns para lidar com valores ausentes MCAR incluem
-
Exclusão de registros com valores ausentes: Se a proporção de valores ausentes é pequena em relação ao tamanho do conjunto de dados, é possível excluir os registros que contêm valores ausentes sem comprometer a análise.
- No entanto, isso pode levar a uma perda de informações valiosas e reduzir o tamanho do conjunto de dados.
-
Imputação de valores: Se o número de valores ausentes é grande, é possível imputar os valores ausentes usando métodos estatísticos, como a média, mediana ou regressão.
- Esses métodos são simples e rápidos, mas podem introduzir um viés nos resultados, dependendo da distribuição dos valores ausentes e da escolha do método de imputação.
-
Modelagem com técnicas de aprendizado de máquina: As técnicas de aprendizado de máquina podem ajudar a prever valores ausentes com base em outros dados disponíveis.
- Essa abordagem pode ser mais precisa do que a imputação de valores, mas também pode ser mais complexa e exigir um conjunto de dados de treinamento grande o suficiente para o modelo aprender a relação entre as variáveis.
Tratamento de valores ausentes não aleatórios
-
O tratamento de valores ausentes não aleatórios (MNAR) é mais complexo do que o tratamento de valores ausentes completamente aleatórios (MCAR), pois os valores ausentes estão relacionados a outras variáveis do conjunto de dados e podem levar a um viés na análise se não forem tratados adequadamente.
-
Algumas técnicas comuns para lidar com valores ausentes MNAR incluem:
- Modelagem com técnicas de aprendizado de máquina: Como os valores ausentes MNAR estão relacionados a outras variáveis do conjunto de dados, a modelagem com técnicas de aprendizado de máquina pode ser uma abordagem útil para prever os valores ausentes com base nas informações disponíveis.
-
Imputação baseada em modelos: A imputação baseada em modelos é uma técnica que envolve a construção de um modelo estatístico para prever os valores ausentes com base nas informações disponíveis.
- Essa abordagem requer um conhecimento prévio da relação entre as variáveis e pode ser mais complexa do que outros métodos de imputação.
-
Análise de sensibilidade: A análise de sensibilidade é uma técnica que envolve testar diferentes cenários e valores de imputação para avaliar o impacto nos resultados da análise.
- Essa abordagem pode ajudar a identificar os valores mais plausíveis para a imputação e a avaliar a robustez dos resultados.
Tratamento de valores inconsistentes
- O tratamento de valores inconsistentes é importante para garantir a qualidade e a confiabilidade dos dados, pois valores inconsistentes podem afetar negativamente a análise e a interpretação dos resultados.
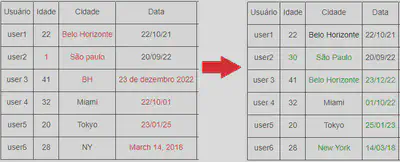
-
Algumas técnicas comuns para lidar com valores inconsistentes incluem:
- Identificação de valores inconsistentes: Verifica-se os valores em cada variável, comparando-os com os valores esperados ou com outras fontes de dados. Também é possível usar técnicas de detecção de outliers para identificar valores inconsistentes automaticamente.
-
Correção manual: Para valores inconsistentes que podem ser facilmente corrigidos, a correção manual pode ser uma abordagem eficaz.
- Isso pode incluir a revisão manual dos dados e a correção de erros, como erros de digitação ou valores fora do intervalo esperado.
-
Imputação de valores: Para valores inconsistentes que não podem ser facilmente corrigidos, a imputação de valores pode ser uma abordagem útil.
- Isso envolve a substituição de valores inconsistentes por valores estimados com base em outras informações disponíveis no conjunto de dados.
-
Exclusão de registros: Para valores inconsistentes que não podem ser corrigidos e não podem ser imputados com precisão, a exclusão de registros pode ser uma abordagem apropriada.
- Isso envolve a remoção dos registros com valores inconsistentes do conjunto de dados.